Performance Stress Testing in Siraya AI AI
Overview
Performance testing, also known as stress or load testing, is a technical process used to evaluate how a system performs under specific workloads. For network devices such as Siraya AI AI, performance testing helps determine its capacity limits, stability, and efficiency in handling large volumes of requests or traffic.
The primary measurement indicators include:
- QPS (Queries per Second): The number of requests the router can successfully process per second.
- Latency (Response Time): The time taken for a request to be processed and a response returned.
- Throughput: The total amount of data that can be transmitted over the network per unit time.
- Packet Loss Rate: The percentage of packets that are dropped during transmission.
- CPU and Memory Utilization: Hardware resource usage during high-load scenarios.
Testing Objectives
Performance testing ensures that Siraya AI AI:
- Maintains stable performance under expected peak loads.
- Handles abnormal or sudden traffic surges without network interruption.
- Meets service level agreements (SLAs) for latency and throughput.
- Provides clear data points for capacity planning and future optimization.
Testing Guide
1. Environment Setup
Requirements:
- Python ≥ 3.9
requestsorhttpx- Access to Siraya AI AI and direct model endpoints.
2. Account & API Keys Setup
The first step to start using Siraya AI is to create an account and get your API key.
The second step to start using Google AI Studio is create a project and get your API Key.
3. Code Script Example
import time
import argparse
import os
from concurrent.futures import ThreadPoolExecutor, as_completed
from typing import Dict, Any, Optional
from openai import OpenAI
def create_client(base_url: str, api_key: str) -> OpenAI:
return OpenAI(base_url=base_url, api_key=api_key)
def send_request(client: OpenAI, model: str, prompt: str) -> Dict[str, Any]:
start = time.perf_counter()
usage: Optional[Dict[str, int]] = None
status_ok = False
try:
completion = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
extra_body={"usage": {"include": True}},
)
status_ok = True
usage_obj = getattr(completion, "usage", None)
if usage_obj:
usage = {
"prompt_tokens": getattr(usage_obj, "prompt_tokens", 0) or 0,
"completion_tokens": getattr(usage_obj, "completion_tokens", 0) or 0,
"total_tokens": getattr(usage_obj, "total_tokens", 0) or 0,
}
except Exception as e:
return {
"ok": False,
"error": str(e),
"latency_ms": (time.perf_counter() - start) * 1000,
"finished_at": time.perf_counter(),
"usage": usage,
}
return {
"ok": status_ok,
"latency_ms": (time.perf_counter() - start) * 1000,
"finished_at": time.perf_counter(),
"usage": usage,
}
def percentile(values, p):
if not values:
return 0.0
s = sorted(values)
k = max(0, min(len(s) - 1, int(round((p / 100.0) * (len(s) - 1)))))
return s[k]
def print_summary(results, wall_time_s):
latencies = [r["latency_ms"] for r in results]
ok_count = sum(1 for r in results if r["ok"])
err_count = len(results) - ok_count
avg_latency = sum(latencies) / len(latencies) if latencies else 0.0
p50 = percentile(latencies, 50)
p90 = percentile(latencies, 90)
p95 = percentile(latencies, 95)
p99 = percentile(latencies, 99)
total_tokens = 0
for r in results:
u = r.get("usage")
if u and isinstance(u, dict):
total_tokens += int(u.get("total_tokens", 0) or 0)
rpm_overall = (len(results) / (wall_time_s / 60.0)) if wall_time_s > 0 else 0.0
tpm_overall = (total_tokens / (wall_time_s / 60.0)) if wall_time_s > 0 else 0.0
print("Summary")
print(f"Requests: {len(results)}, Success: {ok_count}, Errors: {err_count}")
print(f"Wall Time: {wall_time_s:.2f}s, RPS: {len(results)/wall_time_s if wall_time_s>0 else 0:.2f}")
print(f"Latency(ms): avg={avg_latency:.2f}, p50={p50:.2f}, p90={p90:.2f}, p95={p95:.2f}, p99={p99:.2f}")
print(f"RPM Overall: {rpm_overall:.2f}")
print(f"TPM Overall: {tpm_overall:.2f}")
def print_minute_breakdown(results, start_wall):
buckets: Dict[int, Dict[str, Any]] = {}
for r in results:
finished_at = r["finished_at"]
minute_idx = int((finished_at - start_wall) // 60)
b = buckets.setdefault(minute_idx, {"requests": 0, "tokens": 0})
b["requests"] += 1
u = r.get("usage")
if u and isinstance(u, dict):
b["tokens"] += int(u.get("total_tokens", 0) or 0)
print("Per-Minute")
for k in sorted(buckets.keys()):
b = buckets[k]
print(f"Minute {k}: RPM={b['requests']}, TPM={b['tokens']}")
def run_qps_mode(qps: float, duration_s: int, concurrency: int, base_url: str, api_key: str, model: str, prompt: str):
client = create_client(base_url, api_key)
total_requests = int(qps * duration_s)
results = []
start_wall = time.perf_counter()
with ThreadPoolExecutor(max_workers=concurrency) as executor:
futures = []
start_schedule = time.perf_counter()
for i in range(total_requests):
next_time = start_schedule + i / qps
now = time.perf_counter()
sleep_s = next_time - now
if sleep_s > 0:
time.sleep(sleep_s)
futures.append(executor.submit(send_request, client, model, prompt))
for f in as_completed(futures):
results.append(f.result())
wall_time_s = time.perf_counter() - start_wall
print_summary(results, wall_time_s)
print_minute_breakdown(results, start_wall)
def run_burst_mode(tasks: int, concurrency: int, base_url: str, api_key: str, model: str, prompt: str):
client = create_client(base_url, api_key)
results = []
start_wall = time.perf_counter()
with ThreadPoolExecutor(max_workers=concurrency) as executor:
futures = [executor.submit(send_request, client, model, prompt) for _ in range(tasks)]
for f in as_completed(futures):
results.append(f.result())
wall_time_s = time.perf_counter() - start_wall
print_summary(results, wall_time_s)
print_minute_breakdown(results, start_wall)
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str, default="qps", choices=["qps", "burst"])
parser.add_argument("--qps", type=float, default=10.0)
parser.add_argument("--duration", type=int, default=60)
parser.add_argument("--concurrency", type=int, default=4)
parser.add_argument("--tasks", type=int, default=200)
parser.add_argument("--base-url", type=str, default="https://llm.siraya.pro/v1")
parser.add_argument("--api-key", type=str, default="")
parser.add_argument("--model", type=str, default="vertex/qwen3-next-80b-a3b-instruct")
parser.add_argument("--prompt", type=str, default="What is the meaning of life?")
args = parser.parse_args()
if not args.api_key:
raise SystemExit("Missing --api-key or ONEROUTER_API_KEY")
if args.mode == "qps":
run_qps_mode(args.qps, args.duration, args.concurrency, args.base_url, args.api_key, args.model, args.prompt)
else:
run_burst_mode(args.tasks, args.concurrency, args.base_url, args.api_key, args.model, args.prompt)
if __name__ == "__main__":
main()
4. Run Testing
python3 Siraya AI/llm_load_test.py --qps 16.67 --duration 120 --concurrency 150 --model "vertex/qwen3-next-80b-a3b-instruct" --api-key "Replace with your key"
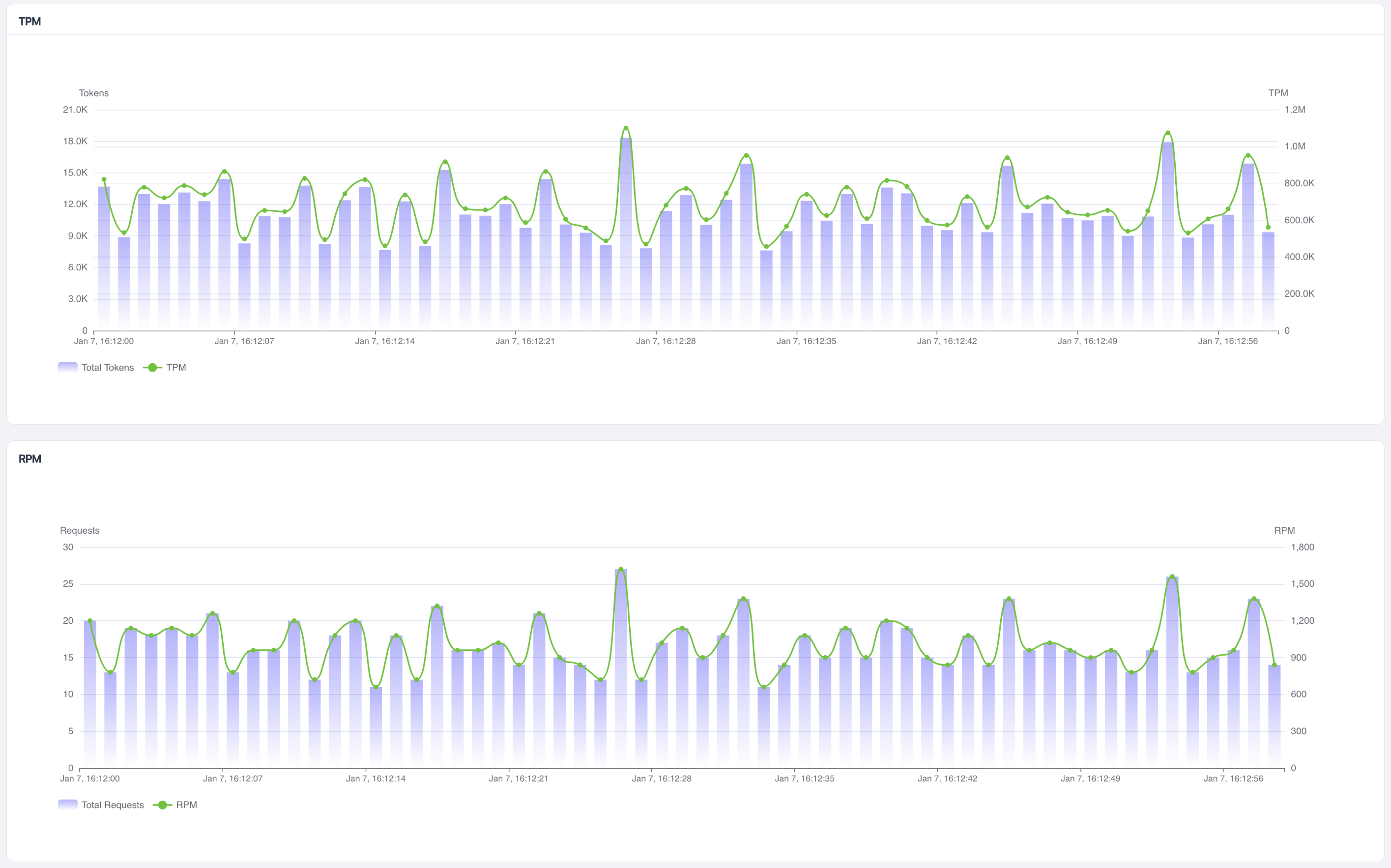
Summary
Requests: 2000, Success: 2000, Errors: 0
Wall Time: 125.86s, RPS: 15.89
Latency(ms): avg=4657.20, p50=4602.80, p90=5634.60, p95=5997.43, p99=7177.60
RPM Overall: 953.41
TPM Overall: 649570.29
Per-Minute
Minute 0: RPM=917, TPM=625730
Minute 1: RPM=1022, TPM=695261
Minute 2: RPM=61, TPM=41634